
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- zepettoworld.com
- DispatcherServlet
- git #gitlab #github
- spring
- Bean
- layout #thymeleaf #화면분할
- 스프링
- autowired
- 1
- 스프링 부트
- 오토와이어드
- Component
- Today
- Total
기록과 정리
엔티티 매핑 ( Entity Mapping ) 본문
이 글은 김영한님의 자바 ORM 표준 JPA 프로그래밍 강의를 참고하였습니다.
www.inflearn.com/course/ORM-JPA-Basic/lecture/21695?tab=curriculum
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다. 초급 웹 개발 프로그
www.inflearn.com
@Entity
클래스에 @Entity 어노테이션을 붙이면 JPA가 관리하는 엔티티이다. 단, 기본 생성자는 필수
Entity의 속성값으로는 대표적으로 @Table이 있다. @Table은 매핑할 테이블의 이름(name) , 데이터베이스 catalog매핑 (catalog), schema 매핑 (schema) , uniqueConstraints ( DDL 생성시 유니크 제약 조건 생성 ) 등이 가능하다.
데이터 베이스 스키마 자동 생성 - hibernate.hbm2ddl.auto
하이버네이트에서 데이터 베이스 스키마 자동 생성해주는 속성이다.
<property name="hibernate.hbm2ddl.auto" value="create" />
value 값에는 5가지로 분류 가능하다.
1. create - 기존 테이블을 삭제 후 다시 생성
2. create-drop - create와 같지만 종료시점에 테이블을 drop
3. update - 변경분만 반영
4. validate - 엔티티와 테이블이 매핑이 되었는지 확인
5. none - 옵션이 없거나 생략됨을 의미 ( 실제로 none은 존재하지 않는다 )
주의점 )
운영 장비에는 절대 create, create-drop, update 사용하면 안된다
개발 초기 단계는 create 또는 update
테스트 서버는 update 또는 validate
스테이징과 운영 서버는 validate 또는 none -> 쿼리를 만들어줄때, 직접 다듬은 후 만들어서 넘겨주기도 한다.
매핑 어노테이션
매핑 어노테이션에도 5가지로 정리할 수 있다.
1. @Column
컬럼 매핑으로 이름(name)과 등록 또는 수정 여부 (insertable, updatable), null값의 허용 여부 (nullable)등을 설정 가능하다. 실제 DB에서의 관행으로 order_item, menu_id 또는 MENU_ID , BOARD_NAME과 같은 이름을 짓는데 비지니스 로직에서 사용하는 인스턴스와 DB 컬럼명이 다른 경우 많이 사용한다.
2. @Temporal
날짜 타입 매핑
JDK 8 version 에서 LocalDate , LocalDateTime을 사용시에는 최신 하이버네이트 지원으로 생략 가능 하다.
3. @Enumerated
Enum타입을 매핑할 때 사용.
EnumType.ORDINAL ( 순서를 DB에 저장 ) 은 지양하자. EnumType.String ( 이름을 DB에 저장 )을 사용을 하도록 할것
개발 중간에 새로운 Enum 이 발생할 경우, 순서가 DB에 저장될때 구분하기 힘든 경우가 발생한다.
4. @Lob
데이터 베이스 BLOB, CLOB 매핑
CLOB - String, char...
BLOB - Byte..
지정할 속성은 없다.
5. @Transient
'필드를 매핑하지 않을 때' 사용, 엔티티와 별개로 비지니스 로직에서만 사용할 경우 사용한다.
기본 키 매핑
PK를 매핑할 경우 2가지 할당 방법이 있다.
1. @ID - 직접 ID값 사용
2. @GeneratedValue - 이하 4가지 전략이 존재
- IDENTITY
- SEQUENCE
- TABLE
- AUTO
IDENTITY 전략의 예외점

해당 전략은 특이하게 DB에게 위임을 하는 방식이다. 하지만 애매한 점이 있다면 보통 DB에 커밋되는 시점에 영속성컨텍스트에서 DB로 쿼리전달이 된다. @GeneratedValue로 다음 PK를 알기 위해서는 DB에 한번 조회해봐야 PK를 알 수 있다..
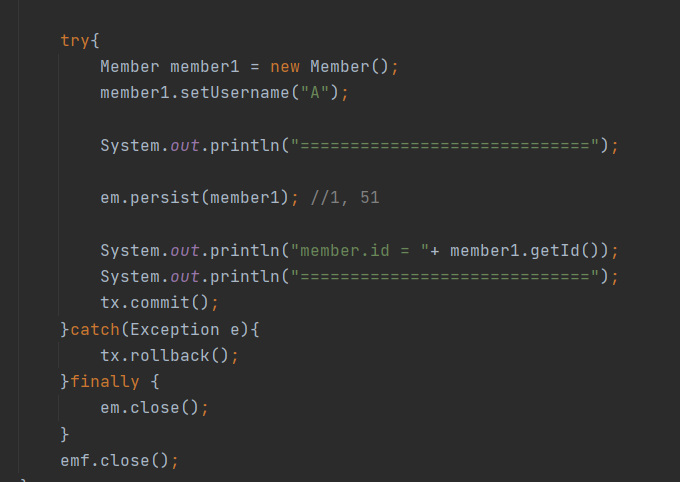
해당 코드는 member1에 id값을 할당하지 않고 persist 하는 코드이다.
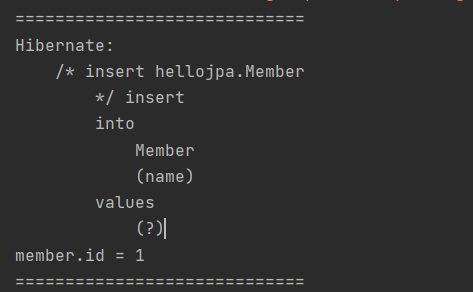
보이는 것과 같이 commit 시점전에 persist함과 동시에 쿼리가 db로 날라감(?)을 볼 수 있다.
identity 전략의 예외라고 볼 수 있다.
sequence 전략의 특징 - - @SequenceGenerator
| 속성 | 설명 | 기본값 |
| name | 식별자 생성기 이름 | 필수 |
| table | 키생성 테이블 명 | hibernate_sequences |
| pkColumnName | 시퀀스 컬럼명 | sequence_name |
| pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
| valueColumnNa | 시퀀스 값 컬럼명 | next_val |
| initialValue | 키로 사용할 값 이름 | 0 |
| allocationSize | 초기 값, 마지막으로 생성된 값이 기준이다. | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 | |
| uniqueConstraints(DDL) |
em.persist 하는 시점에 sequence에서 pk를 가져와야한다. 따라서 persist하기 전 , PK값을 DB에서 가져온 후, 영속성 컨테스트에 저장을 한다.
즉 persist할 때 , '어라? sequence전략이네?'하고 db에서 id값을 가져온 후 id값을 할당해준다. 그러면 inset쿼리는 실제 transaction 실행되는 시점에 쿼리가 반영된다.
그러면... 성능 이점이 있는가? 라는 의문이 있을 수 있다.
allocationSize 최적화
allocationSize (default 50) 은 시퀀스 한번 호출에 증가하는 수를 지정해놓은 것이다. 즉 DB 1번 갔다 올 때마다, 시퀀스 값이 50을 가져와서 메모리에 쌓여있는 시퀀스값을 사용한다.
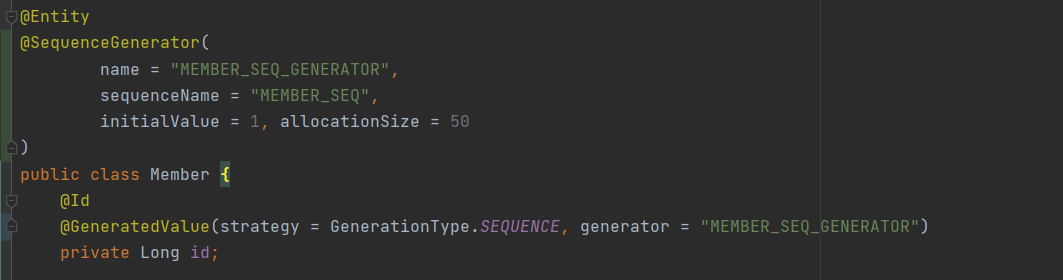
50개만 땡겨줘~(?);;
이러한 방식은 여러 웹서버를 사용해도 동시성 문제를 해결해준다. 실제 코드로 살펴보면
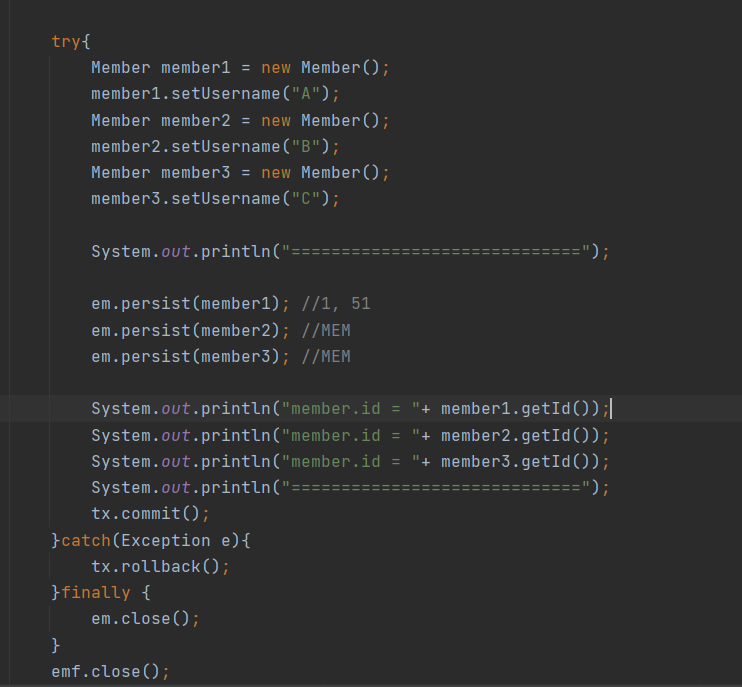
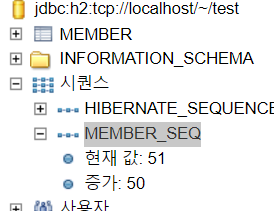
현재값이 51이다...
DB SEQ 가져온값 / 어플리케이션에서 사용하는값
1 / 1
51 / 2
51 / 3
정리하면 2번째 호출(persist)에서 1번째 호출과 달리 50개를 가져왔다. 그리고 기존에 JPA 메모리에 저장되어진 SEQ를 3번쨰 persist에서 사용했다.
이런식으로 allocationSize 를 사용해서 DB 직접 호출을 피할 수 있다. 그러면 50개가 적정한 수 인가? 사실 1000개 10000개 해도 상관없지만 그만큼 웹서버가 내려갈때는 resource 낭비가 된다. 따라서 적정한 수를 정해서 옵션값 설정을 해주도록 하자.
TABLE 전략 - @TableGenerator
sequence전략과 마찬가지로 allocationSize를 통한 성능 최적화가 가능하다.
| 속성 | 설명 | 기본값 |
| name | 식별자 생성기 이름 | 필수 |
| table | 키생성 테이블 명 | hibernate_sequences |
| pkColumnName | 시퀀스 컬럼명 | sequence_name |
| pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
| valueColumnNa | 시퀀스 값 컬럼명 | next_val |
| initialValue | 키로 사용할 값 이름 | 0 |
| allocationSize | 초기 값, 마지막으로 생성된 값이 기준이다. | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 | |
| uniqueConstraints(DDL) |
'IT > JPA' 카테고리의 다른 글
| JPA 고급 매핑 전략 + @MappedSuperclass (0) | 2021.02.20 |
|---|---|
| JPA 연관관계 다중성 ( N:1, 1:N, 1:1, N:M ) (0) | 2021.02.16 |
| JPA 연관관계 매핑 ( 단방향 , 양방향 ) (0) | 2021.02.16 |
| 영속성 컨텍스트 ( Entity Manager ) (0) | 2021.02.09 |
| JPA(Java Persistence API)란? (0) | 2021.02.08 |



